Apache Cassandra
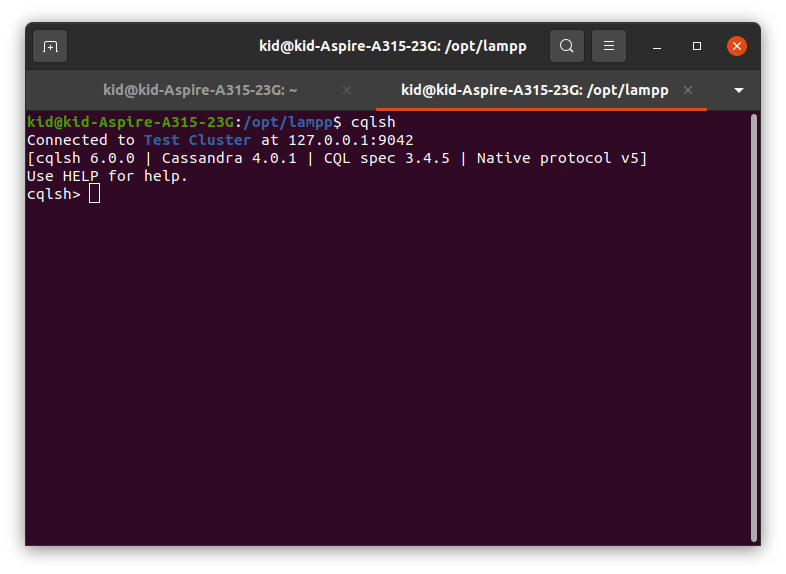
Abrimos un terminal con el siguiente comando:
cqlsh
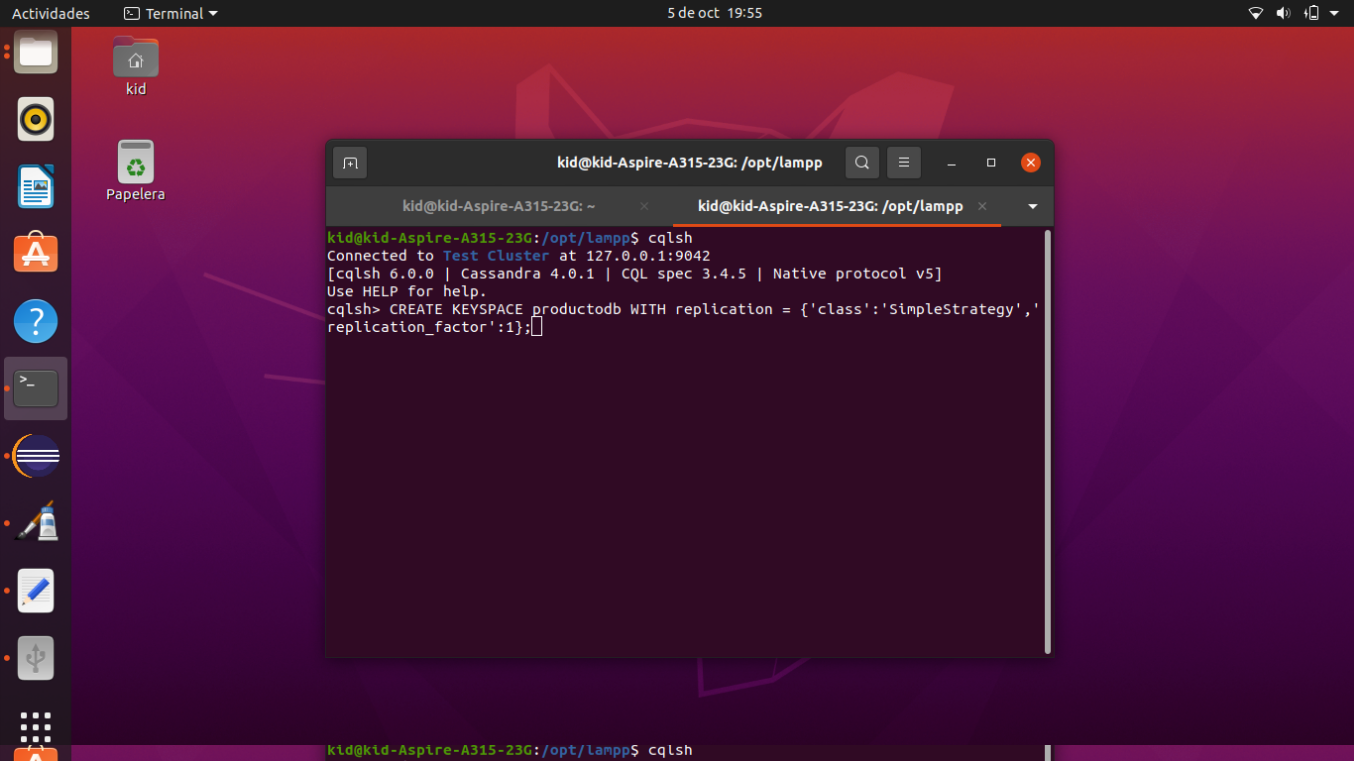
Creamos un keyspace llamado productodb
CREATE KEYSPACE productodb
WITH replication = {'class':'SimpleStrategy','replication_factor':1};
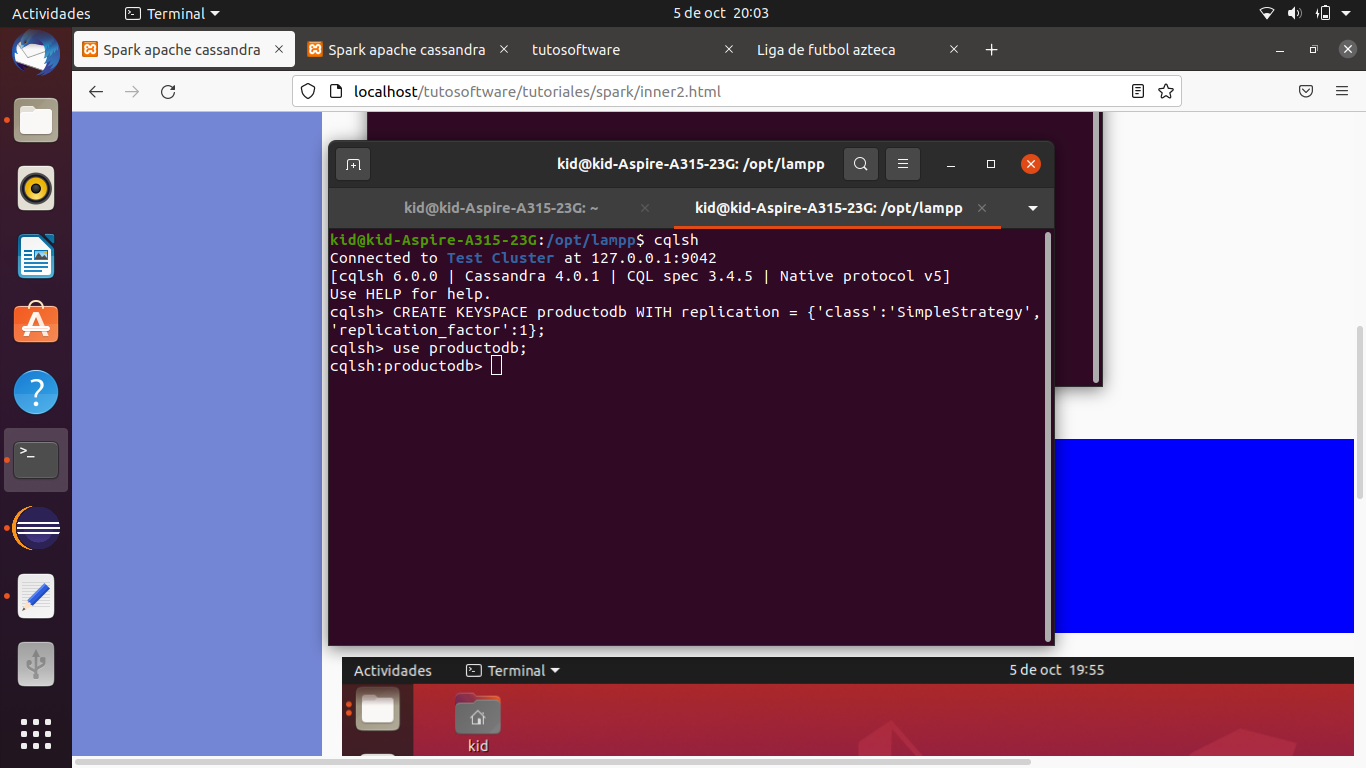
Escribimos
use productodb;
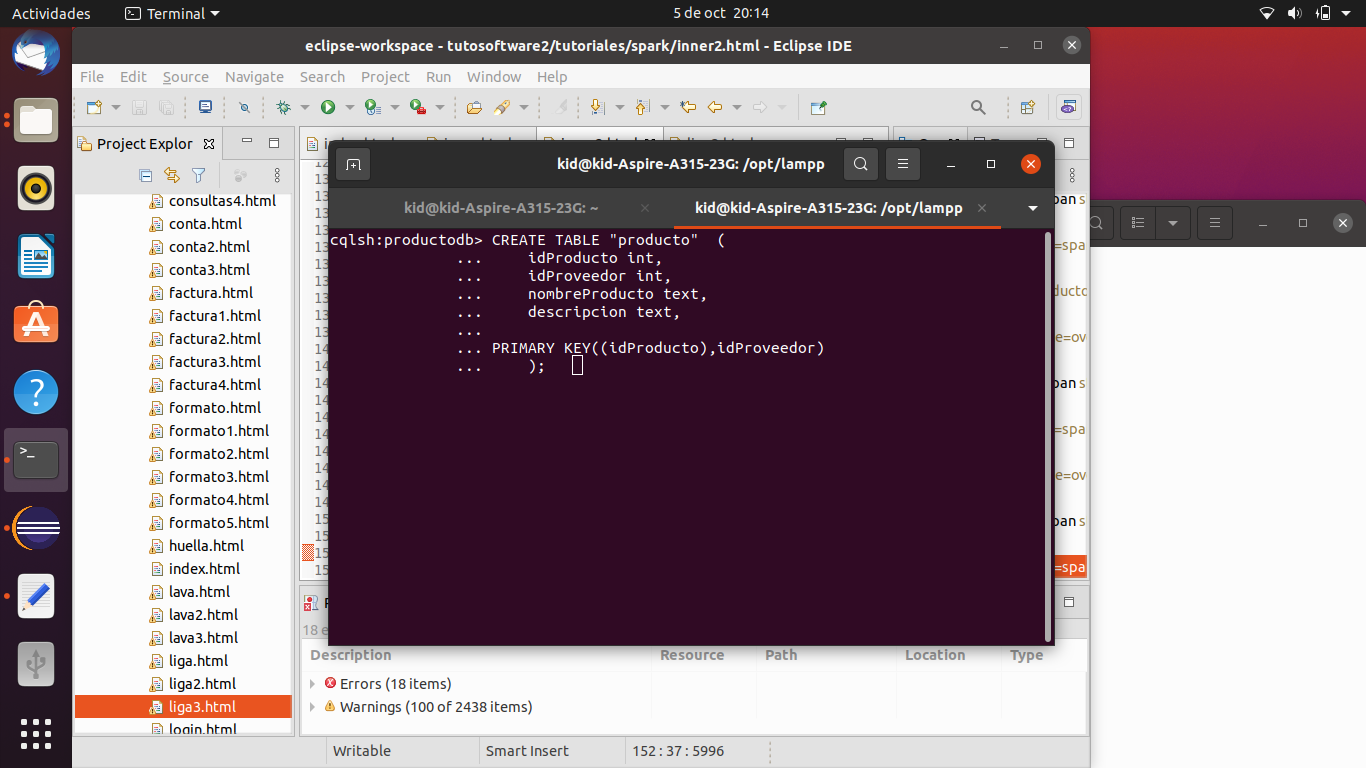
Creamos una tabla llamada producto
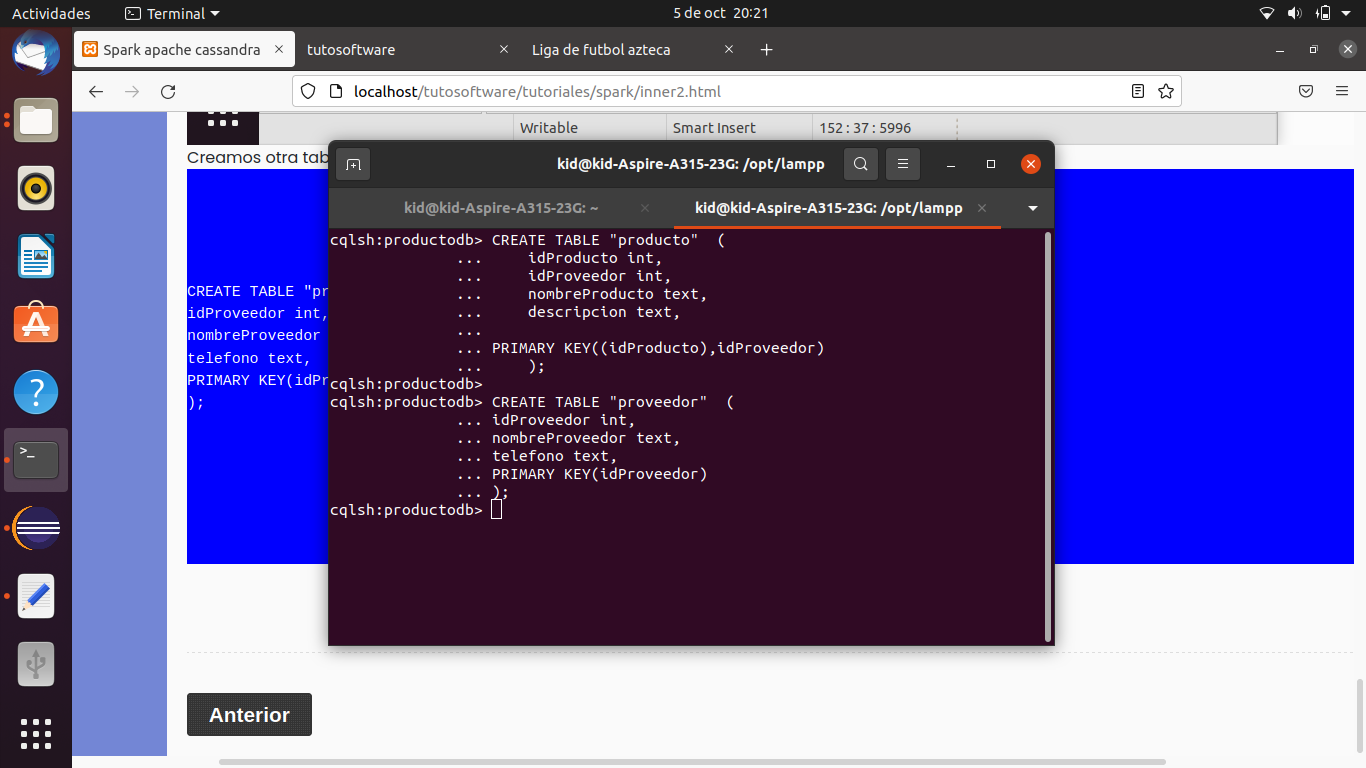
CREATE TABLE "producto" (
idProducto int,
idProveedor int,
nombreProducto text,
descripcion text,
PRIMARY KEY((idProducto),idProveedor)
);
Creamos otra tabla llamada proveedor
CREATE TABLE "proveedor" (
idProveedor int,
nombreProveedor text,
telefono text,
PRIMARY KEY(idProveedor)
);
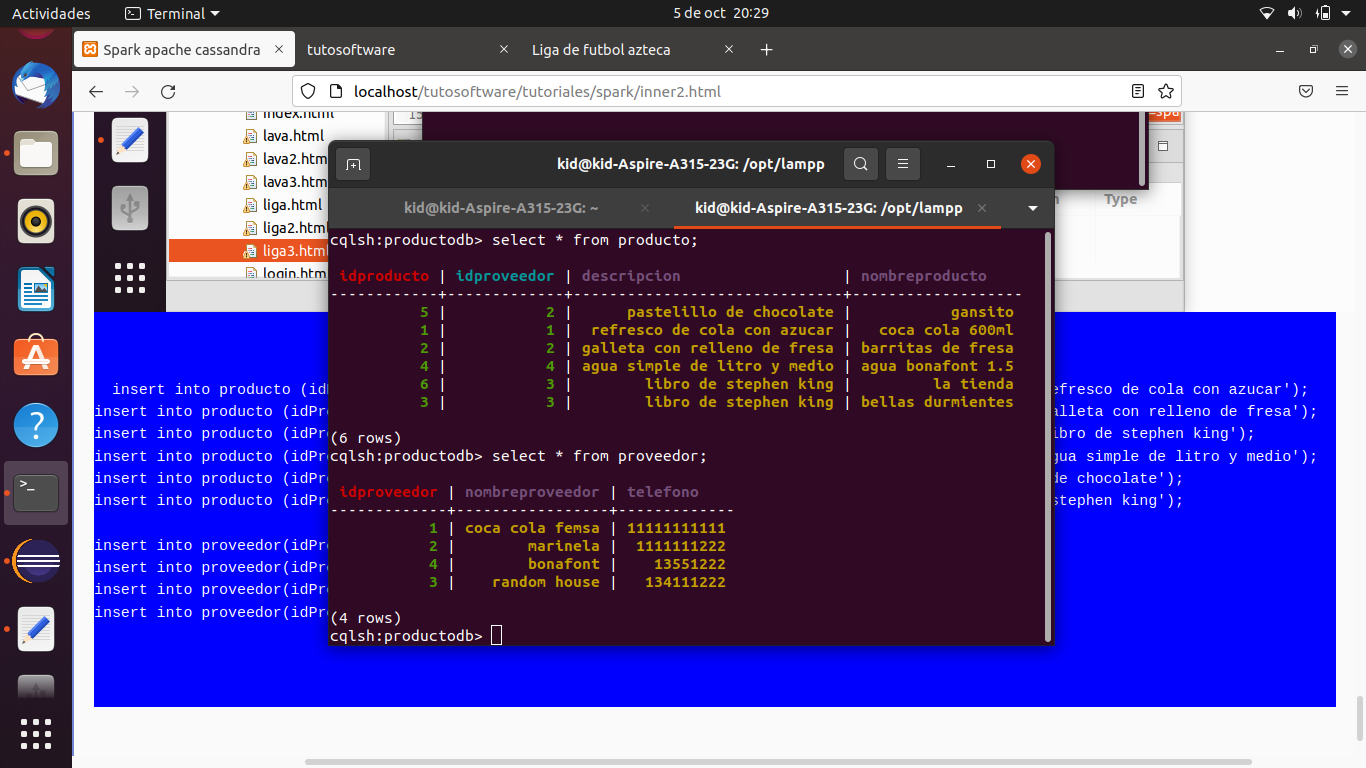
realizamos los siguientes inserts
insert into producto (idProducto,idProveedor,nombreProducto,descripcion) values (1,1,'coca cola 600ml','refresco de cola con azucar');
insert into producto (idProducto,idProveedor,nombreProducto,descripcion) values (2,2,'barritas de fresa','galleta con relleno de fresa');
insert into producto (idProducto,idProveedor,nombreProducto,descripcion) values (3,3,'bellas durmientes','libro de stephen king');
insert into producto (idProducto,idProveedor,nombreProducto,descripcion) values (4,4,'agua bonafont 1.5','agua simple de litro y medio');
insert into producto (idProducto,idProveedor,nombreProducto,descripcion) values (5,2,'gansito','pastelillo de chocolate');
insert into producto (idProducto,idProveedor,nombreProducto,descripcion) values (6,3,'la tienda','libro de stephen king');
insert into proveedor(idProveedor,nombreProveedor,telefono) values(1,'coca cola femsa','11111111111');
insert into proveedor(idProveedor,nombreProveedor,telefono) values(2,'marinela','1111111222');
insert into proveedor(idProveedor,nombreProveedor,telefono) values(3,'random house','134111222');
insert into proveedor(idProveedor,nombreProveedor,telefono) values(4,'bonafont','13551222');