Generación de 100000000 de registros
Vamos a realizar un test de como generar cien millones de registros los vamos a generar mediante un programa java que genere los cien millones mediante un ciclo for y los escriba en un archivo de texto con extensión csv para que spark pueda cargar el archivo hacia apache cassandra el archivo debe tener encabezado de las columnas que deseamos cargar.Creamos un proyecto java los nombramos sparky creamos el paquete com.tutosoftware.generate y sobre este paquete creamos la clase ArchivoCarga y escribimos el siguiente código:
package com.tutosoftware.generate;
import java.io.File;
import java.io.FileWriter;
import java.util.Calendar;
public class ArchivoCarga {
public static void main(String[] args) {
// TODO Auto-generated method stub
try {
File archivo =new File("texto.csv");
Calendar c = Calendar.getInstance();
String dia = Integer.toString(c.get(Calendar.DATE));
String mes = Integer.toString(c.get(Calendar.MONTH));
String anio= Integer.toString(c.get(Calendar.YEAR));
String fecha=dia+"/"+mes+"/"+anio;
FileWriter escribir= new FileWriter(archivo,true);
System.out.println("Escribiendo archivo");
String encabezado ="nombre,telefono,fecha\n";
escribir.write(encabezado);
for(int i=0;i<=100000000;i++) {
String items ="usuario"+i+",5555555555,"+fecha+"\n";
escribir.write(items);
}
System.out.println("Finalizando archivo");
escribir.close();
}catch(Exception e) {
System.out.println("Error al escribir archivo");
}
}
}
Ejecutamos la clase:
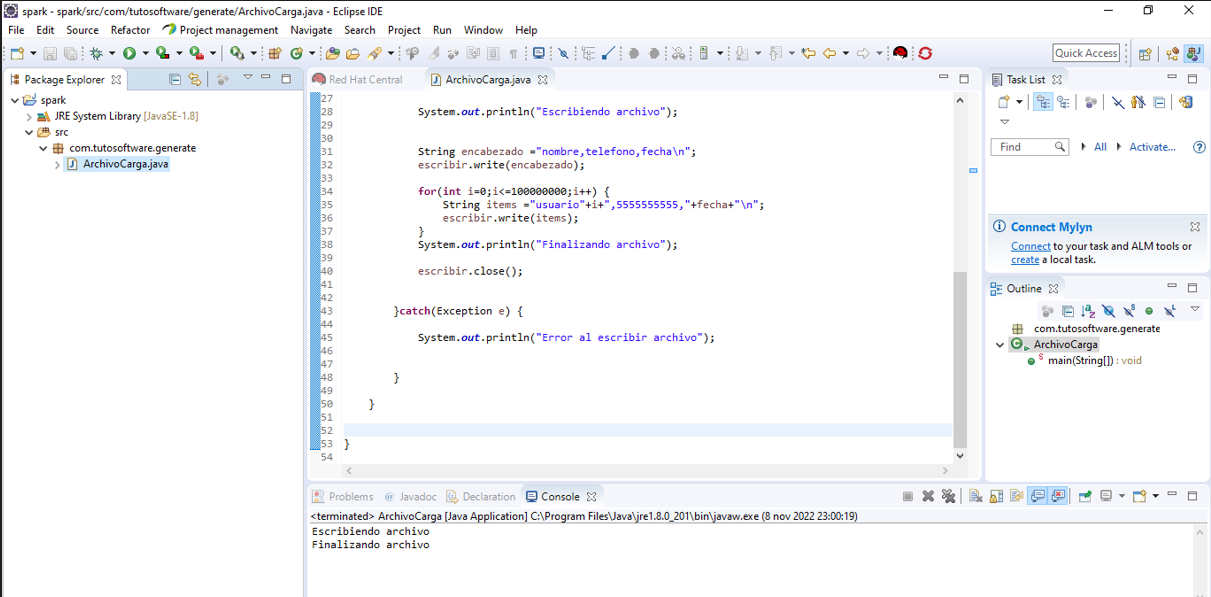
Vemos que se genero el archivo
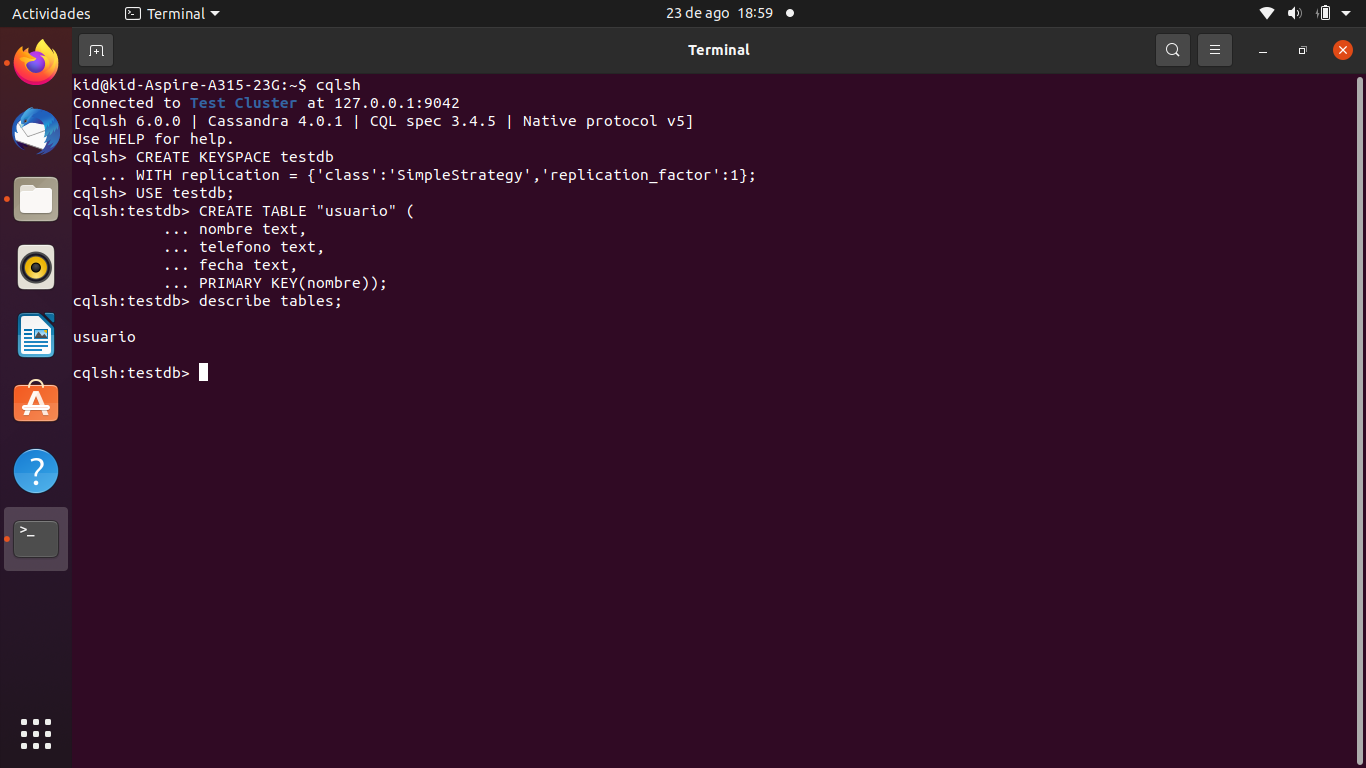
Creación de keyspace
CREATE KEYSPACE testdb
WITH replication = {'class':'SimpleStrategy','replication_factor':1};
USE testdb;
CREATE TABLE "usuario" (
nombre text,
telefono text,
fecha text,
PRIMARY KEY(nombre));
Carga de archivo
El archivo texto.csv lo vamos a cargar en la ruta /home/kid en mi caso es el home, pero ustedes lo pueden cargar en cualquier ruta.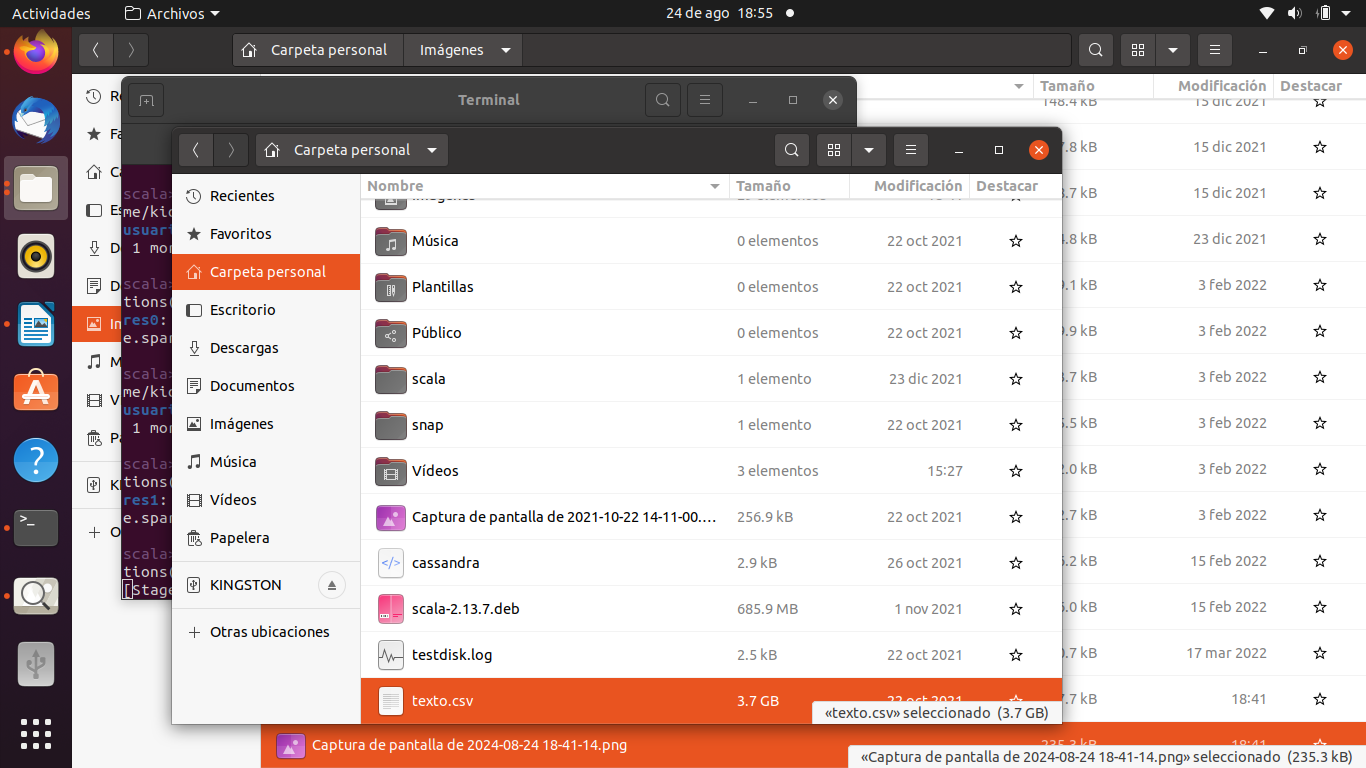
Una vez puesto el archivo en la ruta deseada no olvidar darle los permisos.
chmod 777 texto.csv
Posteriormente abrimos nuestro es spark-shell con el conector de apache cassandra.
spark-shell --packages com.datastax.spark:spark-cassandra-connector_2.12:3.1.0 --conf spark.cassandra.connection.host=127.0.0.1
una vez abierta nuestra consola de spak-shell escribimos lo siguiente:
var usuarios = spark.read.format("csv").option("header","true").load("/home/kid/texto.csv")
usuarios.write.format("org.apache.spark.sql.cassandra").mode("append").options(Map("keyspace"->"testdb","table"->"usuario")).save()
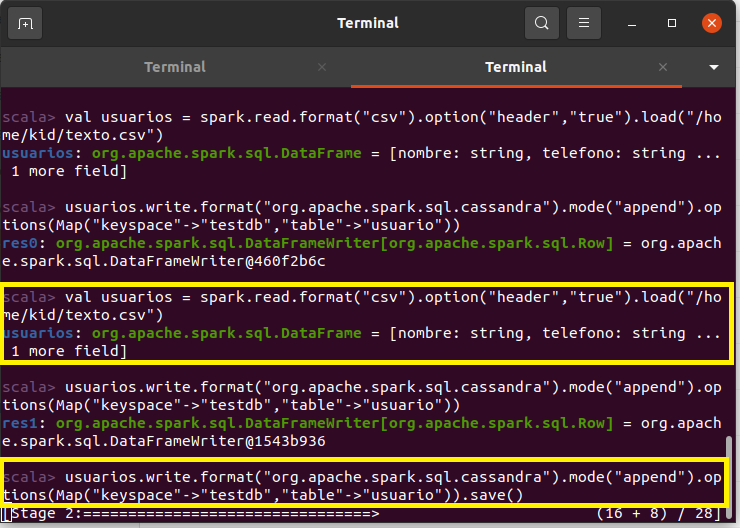
Una vez ejecutados los comandos se empieza a ejecutar la carga de registros y comenzamos a testear abrimos nuestro cqlshell y realizamos la siguiente consulta para vez si se subieron los primeros veinte millones.
select * from usuario where nombre = 'usuario20000000'
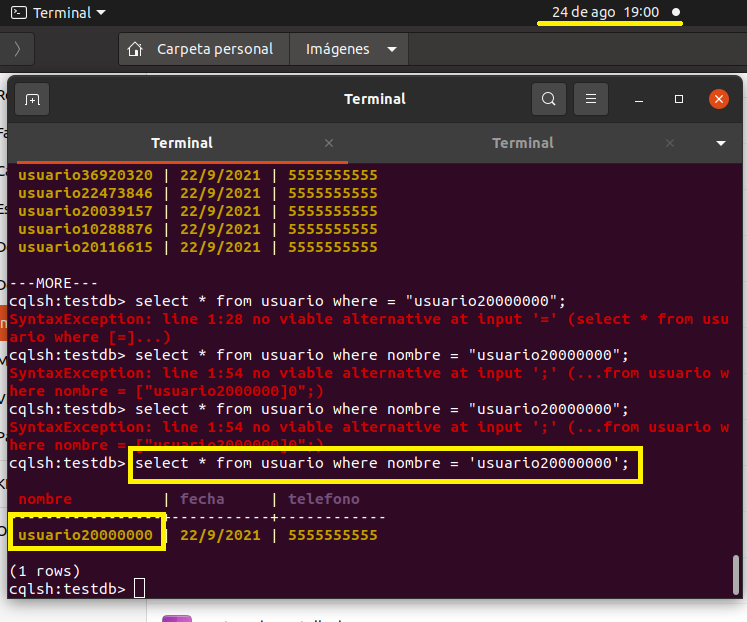
Pasaron 2 minutos más y ya llevamos 30 000 000 como se ven en la pantalla en la columna nombre que una primary key se va mostrando.
select * from usuario where nombre = 'usuario30000000'
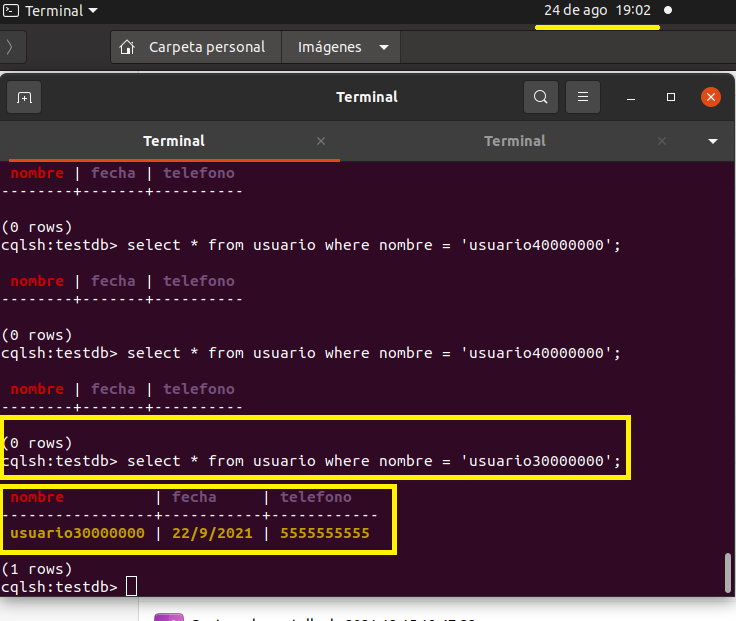
Pasaron 5 minutos y llevamos 39 millones
select * from usuario where nombre = 'usuario39000000'
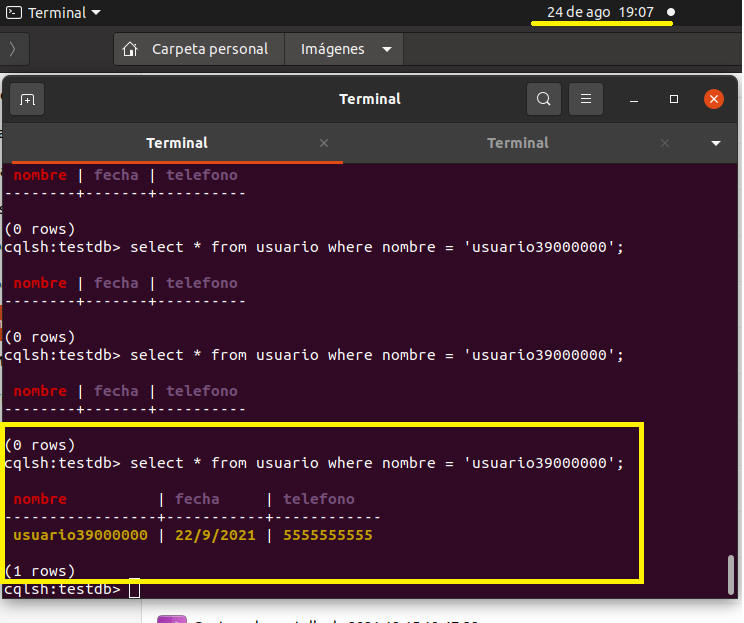
Pasaron 23 minutos y llevamos 65 000 000 de registros
select * from usuario where nombre = 'usuario65000000'
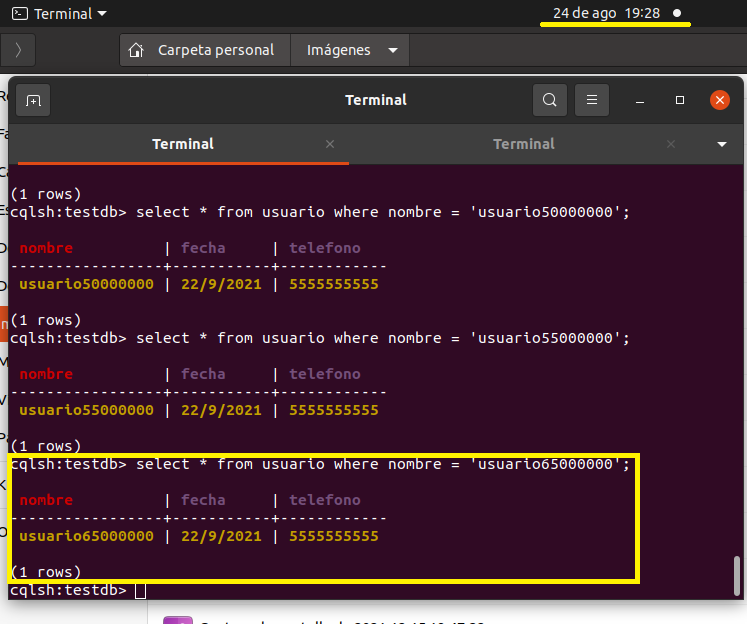
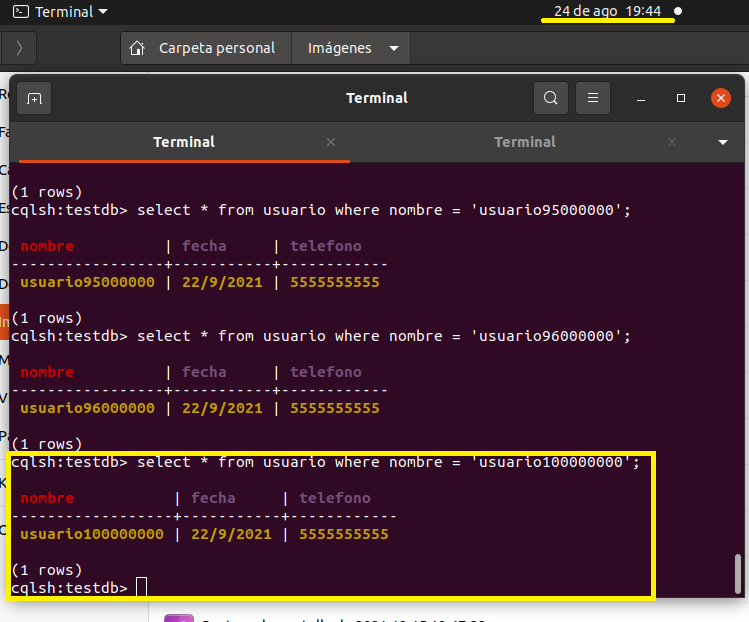
A las 19:35pm que son 7 minutos más llevamos 85 millones insertados
select * from usuario where nombre = 'usuario85000000'
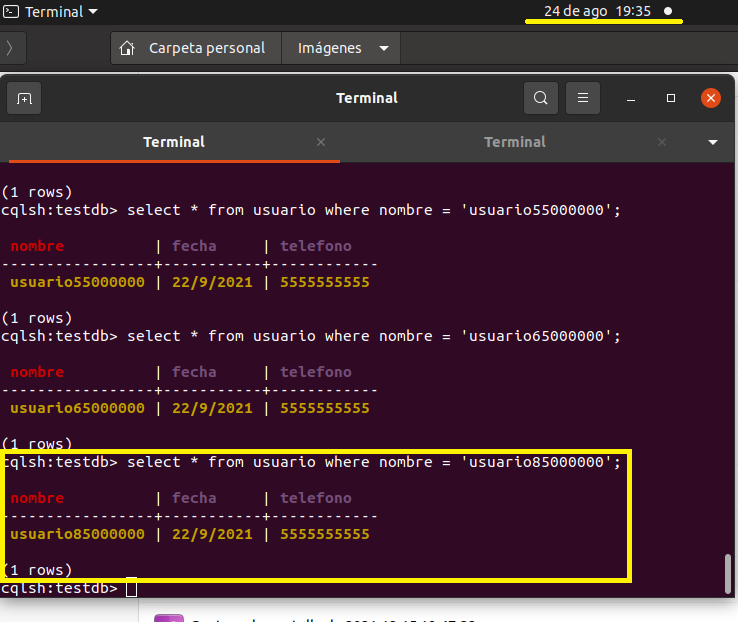
Como a las 19:44 volvi a consultar y efectivamente se agregaron los 100 millones de registros el tiempo aproximado de carga
fue de una hora 6 minutos
select * from usuario where nombre = 'usuario100000000'