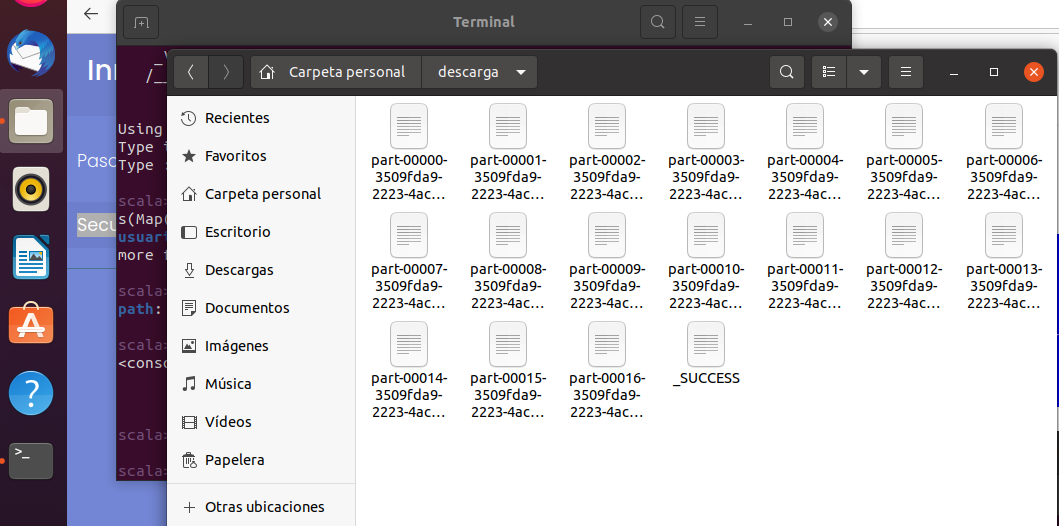
Descarga de los registros
Lo que a continuación vamos a tratar de realizar es la descarga de los cien millones de registros ycolocarlos en archivos de texto.
Lo primero que tenemos que realizar es invocar nuestro spark-shell con su respectivo conector de apache cassandra.
spark-shell --packages com.datastax.spark:spark-cassandra-connector_2.12:3.1.0 --conf spark.cassandra.connection.host=127.0.0.1
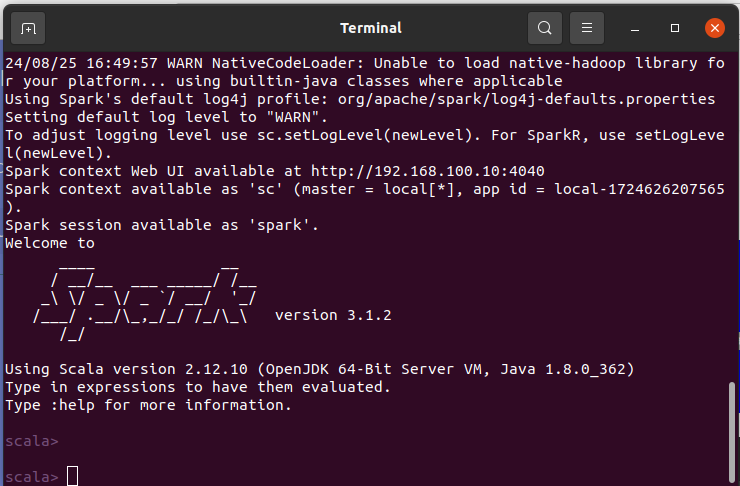
Escribimos el siguiente código
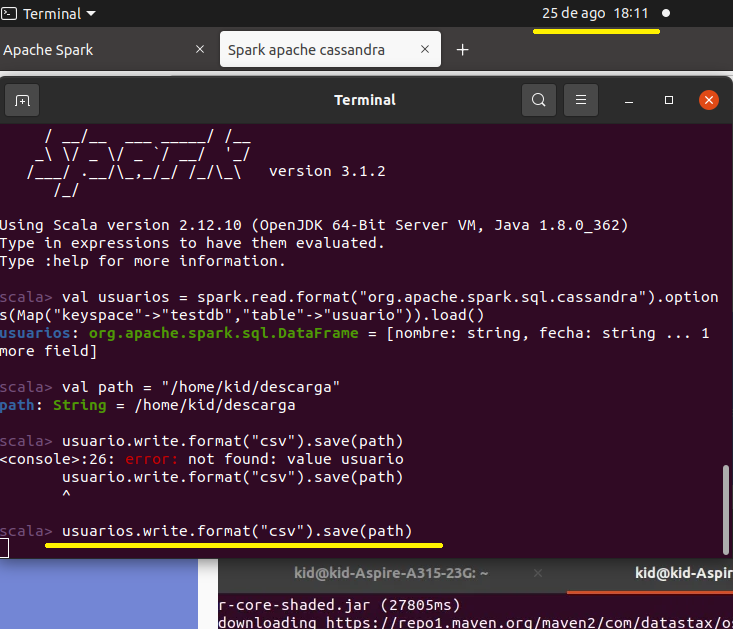
val usuarios = spark.read.format("org.apache.spark.sql.cassandra").options(Map("keyspace"->"testdb","table"->"usuario")).load()
val path="/home/kid/descarga"
usuarios.write.format("csv").save(path)
El comando que escribe lo ejecutamos a 18:11
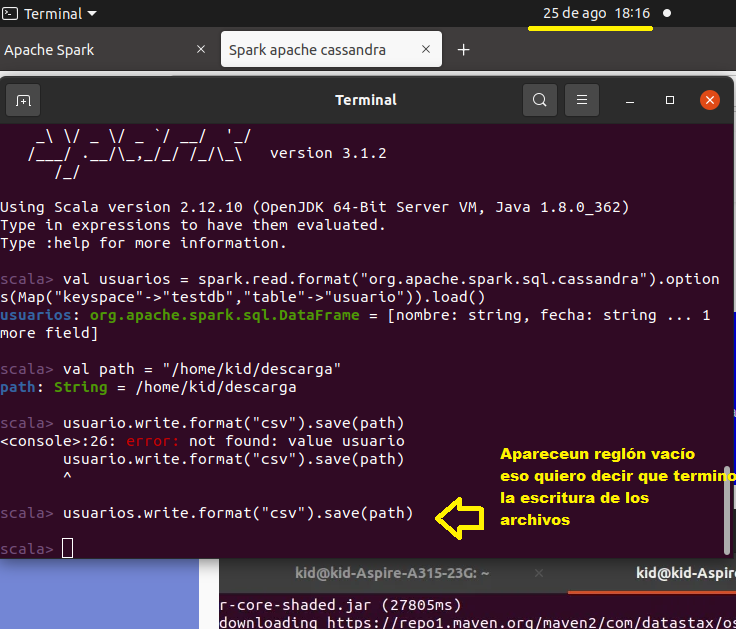
La escritura termino a las 18:15 por lo tanto tardo 5 minutos en descargar 100 millones de registros
El resultado final los registros quedaron el 17 archivos generados